|
|
|
|
|
| adaptivecells/J documentation :: description | |
|
|
AdaptiveCells/J consists of highly customisable
and functionally identical test beans cells. All test bean cells are
structurally identical EJBs; in fact, they contain the same Java
classes. The difference between them is their deployment descriptor,
which can contain different values for key parameters (environment
entries in the EJB deployment descriptor). These values drive the
behaviour and runtime footprint of the test bean cell. Test bean
cells simulate “real” EJBs by emulating computational load (CPU and
memory overhead) and calling other test cells, in different calling
patterns. No code is required (and therefore no compilation) when
using CAT to create a test-bed. Instead, a declarative programming
approach is taken in which XML tags are added to the deployment
descriptors of the participating test beans. The emulation parameters controlling the test bean actions are:
A cell configuration contains zero or one for each of the above parameters. All parameters are optional when specifying a cell configuration. Each test bean cell can contain any number of configurations. A configuration is identified by a configuration name and each of the parameters it contains is labeled with the configuration name in order to separate them from parameters corresponding to other configurations. Test beans expose a single business method, simulateBusinessLogic(). This method has a configuration name as a parameter, which it uses to decide the behaviour it will emulate. For the received configuration name, it will use the corresponding emulation parameters to generate the appropriate overhead (CPU and memory) and call the appropriate target test beans. When calling the target beans, the configuration name is passed on to them (again as a parameter to simulateBusinessLogic()). This ensures that adaptation configurations are preserved across all the participants of an interaction. It is important that the same configuration names be used for all the test beans. This guarantees that if the interaction is started with a configuration, each bean in the interaction “understands” it and therefore can generate the appropriate behaviour. The planning of a particular test configuration (e.g. config1) contains the following steps:
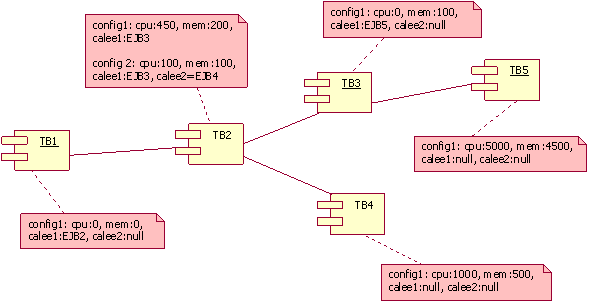
The figure below illustrates a test-bed configuration consisting of 5 Test Beans (TB). The notes attached to each EJB element contain a simplified version of the associated configuration parameters. For TB2, there are two configurations available (they also exist in the other beans but are not shown). In the first configuration, TB2 will call only TB3. In the second configuration, TB2 will call both TB3 and TB4.
|
| © 2005 Adrian Mos | |